publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2026
- Diffusion Models
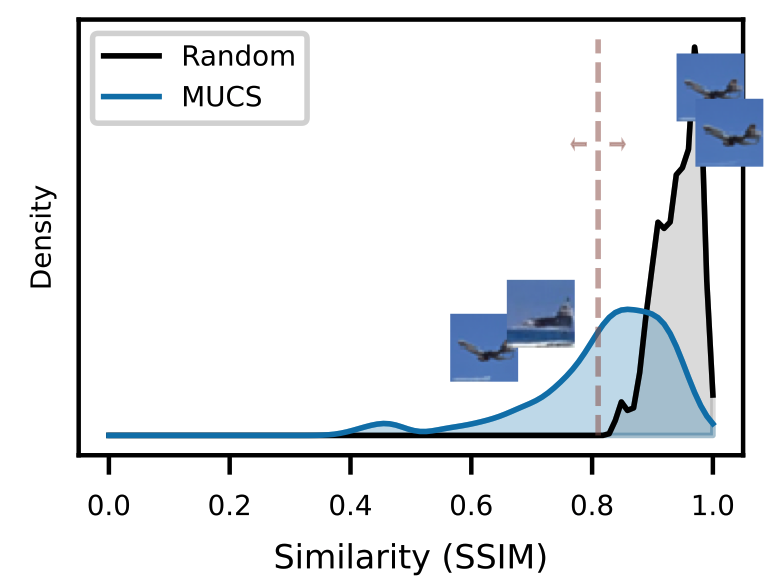 Training data attribution in diffusion models via mirrored unlearning and noise-consistent skewJoan Serrà, Dipam Goswami, Fabio Morreale, Wei-Hsiang Liao, and Yuki MitsufujiIn Arxiv, 2026
Training data attribution in diffusion models via mirrored unlearning and noise-consistent skewJoan Serrà, Dipam Goswami, Fabio Morreale, Wei-Hsiang Liao, and Yuki MitsufujiIn Arxiv, 2026Training data attribution (TDA) should enable generative model interpretability and foster a variety of related downstream tasks. Nonetheless, current TDA approaches lack reliability and robustness, preventing their adoption in real-world setups. In this paper, we take a decisive step towards more reliable and robust TDA for diffusion models. We propose to perform TDA with mirrored unlearning and noise-consistent skew (MUCS). The idea is to fine-tune a second model with bounded mirrored gradient ascent, and to measure the normalized skew of this model with respect to the original one using consistent noise samples. We show that, while being conceptually simple and generic, MUCS systematically outperforms existing methods on three different datasets by a large margin. We additionally study the effect that core design choices have on final performance, and analyze novel aspects regarding the overlap of influential instances across generated items and the potential of ensembling TDA approaches. We believe that our findings may have broader implications for more general unlearning setups, as well as for tasks requiring the comparison of diffusion losses.
- VLMs
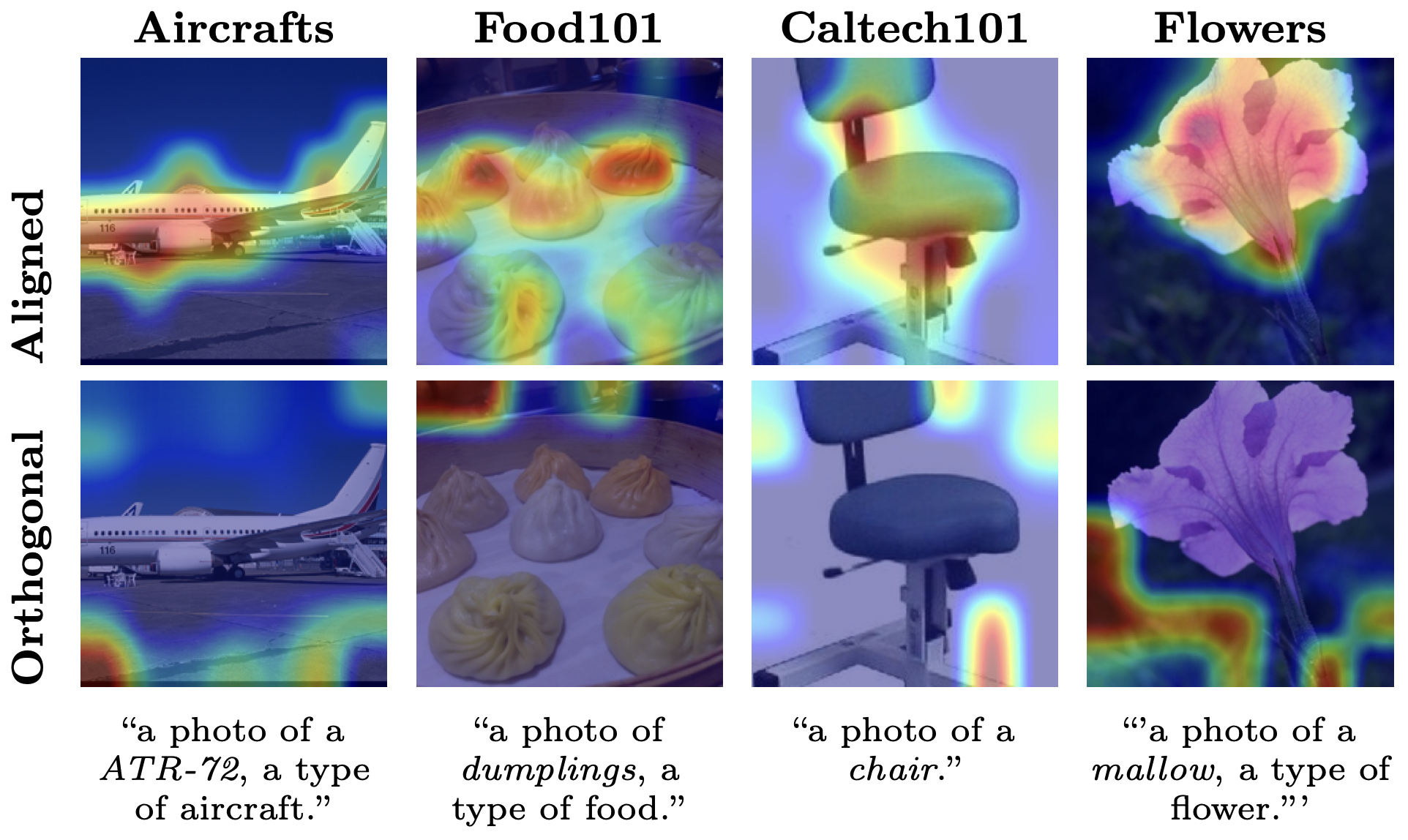 Cross-Modal Prototype Alignment and Mixing for Training-Free Few-Shot ClassificationDipam Goswami, Simone Magistri, Gido Van De Ven, Bartłomiej Twardowski, Andrew D. Bagdanov, Tinne Tuytelaars, and Joost Van De WeijerIn Arxiv, 2026
Cross-Modal Prototype Alignment and Mixing for Training-Free Few-Shot ClassificationDipam Goswami, Simone Magistri, Gido Van De Ven, Bartłomiej Twardowski, Andrew D. Bagdanov, Tinne Tuytelaars, and Joost Van De WeijerIn Arxiv, 2026Vision-language models (VLMs) like CLIP are trained with the objective of aligning text and image pairs. To improve CLIP-based few-shot image classification, recent works have observed that, along with text embeddings, image embeddings from the training set are an important source of information. In this work we investigate the impact of directly mixing image and text prototypes for few-shot classification and analyze this from a bias-variance perspective. We show that mixing prototypes acts like a shrinkage estimator. Although mixed prototypes improve classification performance, the image prototypes still add some noise in the form of instance-specific background or context information. In order to capture only information from the image space relevant to the given classification task, we propose projecting image prototypes onto the principal directions of the semantic text embedding space to obtain a text-aligned semantic image subspace. These text-aligned image prototypes, when mixed with text embeddings, further improve classification. However, for downstream datasets with poor cross-modal alignment in CLIP, semantic alignment might be suboptimal. We show that the image subspace can still be leveraged by modeling the anisotropy using class covariances. We demonstrate that combining a text-aligned mixed prototype classifier and an image-specific LDA classifier outperforms existing methods across few-shot classification benchmarks.
- VLMs
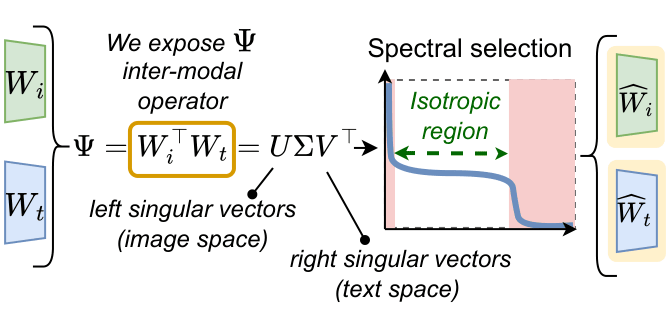 IsoCLIP: Decomposing CLIP Projectors for Efficient Intra-modal AlignmentSimone Magistri, Dipam Goswami, Marco Mistretta, Bartłomiej Twardowski, Joost Van De Weijer, and Andrew D. BagdanovIn Conference on Computer Vision and Pattern Recognition (CVPR), 2026
IsoCLIP: Decomposing CLIP Projectors for Efficient Intra-modal AlignmentSimone Magistri, Dipam Goswami, Marco Mistretta, Bartłomiej Twardowski, Joost Van De Weijer, and Andrew D. BagdanovIn Conference on Computer Vision and Pattern Recognition (CVPR), 2026Vision-Language Models like CLIP are extensively used for inter-modal tasks which involve both visual and text modalities. However, when the individual modality encoders are applied to inherently intra-modal tasks like image-to-image retrieval, their performance suffers from the intra-modal misalignment. In this paper we study intra-modal misalignment in CLIP with a focus on the role of the projectors that map pre-projection image and text embeddings into the shared embedding space. By analyzing the form of the cosine similarity applied to projected features, and its interaction with the contrastive CLIP loss, we show that there is an inter-modal operator responsible for aligning the two modalities during training, and a second, intra-modal operator that only enforces intra-modal normalization but does nothing to promote intra-modal alignment. Via spectral analysis of the inter-modal operator, we identify an approximately isotropic subspace in which the two modalities are well-aligned, as well as anisotropic directions specific to each modality. We demonstrate that this aligned subspace can be directly obtained from the projector weights and that removing the anisotropic directions improves intra-modal alignment. Our experiments on intra-modal retrieval and classification benchmarks show that our training-free method reduces intra-modal misalignment, greatly lowers latency, and outperforms existing approaches across multiple pre-trained CLIP-like models.
2025
- Federated Learning
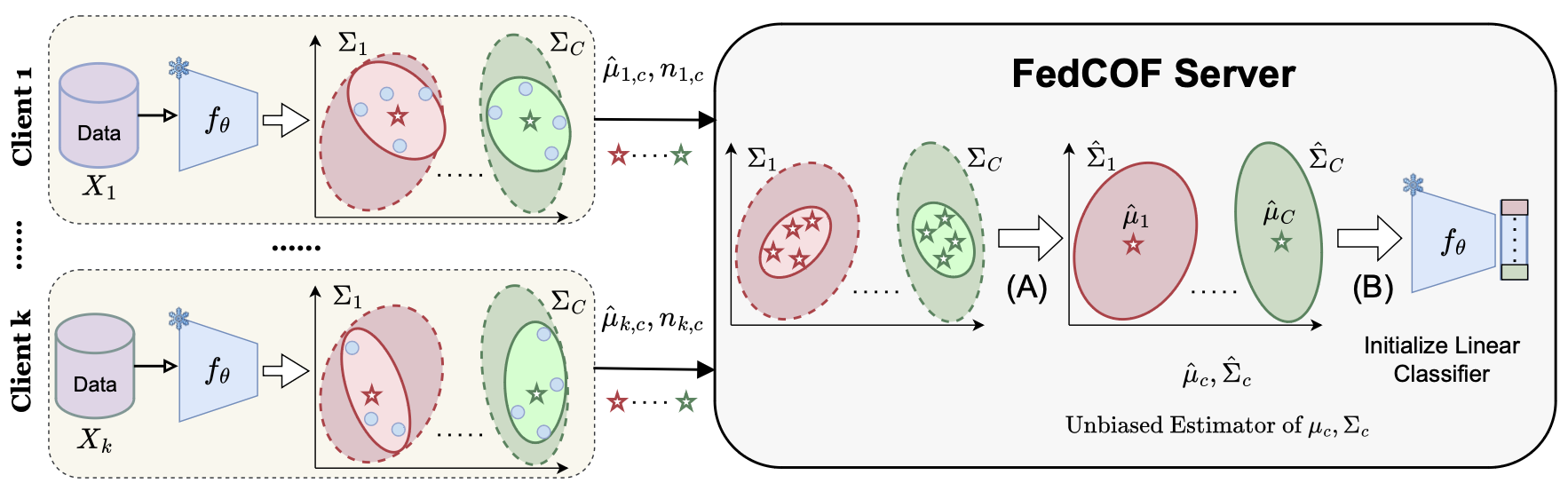 Covariances for Free: Exploiting Mean Distributions for Training-free Federated LearningDipam Goswami, Simone Magistri, Kai Wang, Bartłomiej Twardowski, Andrew D Bagdanov, and Joost Van De WeijerIn Advances in Neural Information Processing Systems (NeurIPS), 2025
Covariances for Free: Exploiting Mean Distributions for Training-free Federated LearningDipam Goswami, Simone Magistri, Kai Wang, Bartłomiej Twardowski, Andrew D Bagdanov, and Joost Van De WeijerIn Advances in Neural Information Processing Systems (NeurIPS), 2025Using pre-trained models has been found to reduce the effect of data heterogeneity and speed up federated learning algorithms. Recent works have explored training-free methods using first- and second-order statistics to aggregate local client data distributions at the server and achieve high performance without any training. In this work, we propose a training-free method based on an unbiased estimator of class covariance matrices which only uses first-order statistics in the form of class means communicated by clients to the server. We show how these estimated class covariances can be used to initialize the global classifier, thus exploiting the covariances without actually sharing them. We also show that using only within-class covariances results in a better classifier initialization. Our approach improves performance in the range of 4-26% with exactly the same communication cost when compared to methods sharing only class means and achieves performance competitive or superior to methods sharing second-order statistics with dramatically less communication overhead. The proposed method is much more communication-efficient than federated prompt-tuning methods and still outperforms them. Finally, using our method to initialize classifiers and then performing federated fine-tuning or linear probing again yields better performance.
- Information Retrieval
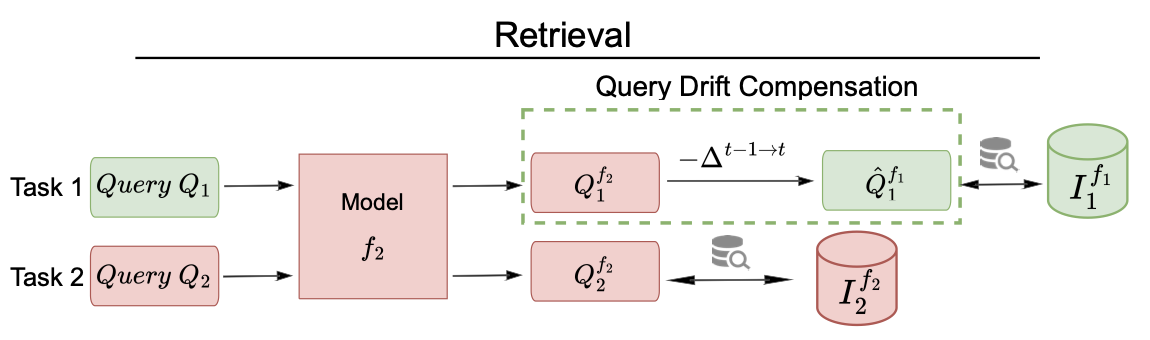 Query Drift Compensation: Enabling Compatibility in Continual Learning of Retrieval Embedding ModelsDipam Goswami, Liying Wang, Bartłomiej Twardowski, and Joost Van De WeijerIn Conference on Lifelong Learning Agents (CoLLAs), 2025
Query Drift Compensation: Enabling Compatibility in Continual Learning of Retrieval Embedding ModelsDipam Goswami, Liying Wang, Bartłomiej Twardowski, and Joost Van De WeijerIn Conference on Lifelong Learning Agents (CoLLAs), 2025Text embedding models enable semantic search, powering several NLP applications like Retrieval Augmented Generation by efficient information retrieval (IR). However, text embedding models are commonly studied in scenarios where the training data is static, thus limiting its applications to dynamic scenarios where new training data emerges over time. IR methods generally encode a huge corpus of documents to low-dimensional embeddings and store them in a database index. During retrieval, a semantic search over the corpus is performed and the document whose embedding is most similar to the query embedding is returned. When updating an embedding model with new training data, using the already indexed corpus is suboptimal due to the non-compatibility issue, since the model which was used to obtain the embeddings of the corpus has changed. While re-indexing of old corpus documents using the updated model enables compatibility, it requires much higher com- putation and time. Thus, it is critical to study how the already indexed corpus can still be effectively used without the need of re-indexing. In this work, we establish a continual learning benchmark with large-scale datasets and continually train dense retrieval embedding models on query-document pairs from new datasets in each task and observe forgetting on old tasks due to significant drift of embeddings. We employ embedding distillation on both query and document embeddings to maintain stability and propose a novel query drift compensation method during retrieval to project new model query embeddings to the old embedding space. This enables compatibility with previously indexed corpus embeddings extracted using the old model and thus reduces the forgetting. We show that the proposed method significantly improves performance without any re-indexing.
2024
- Continual Learning
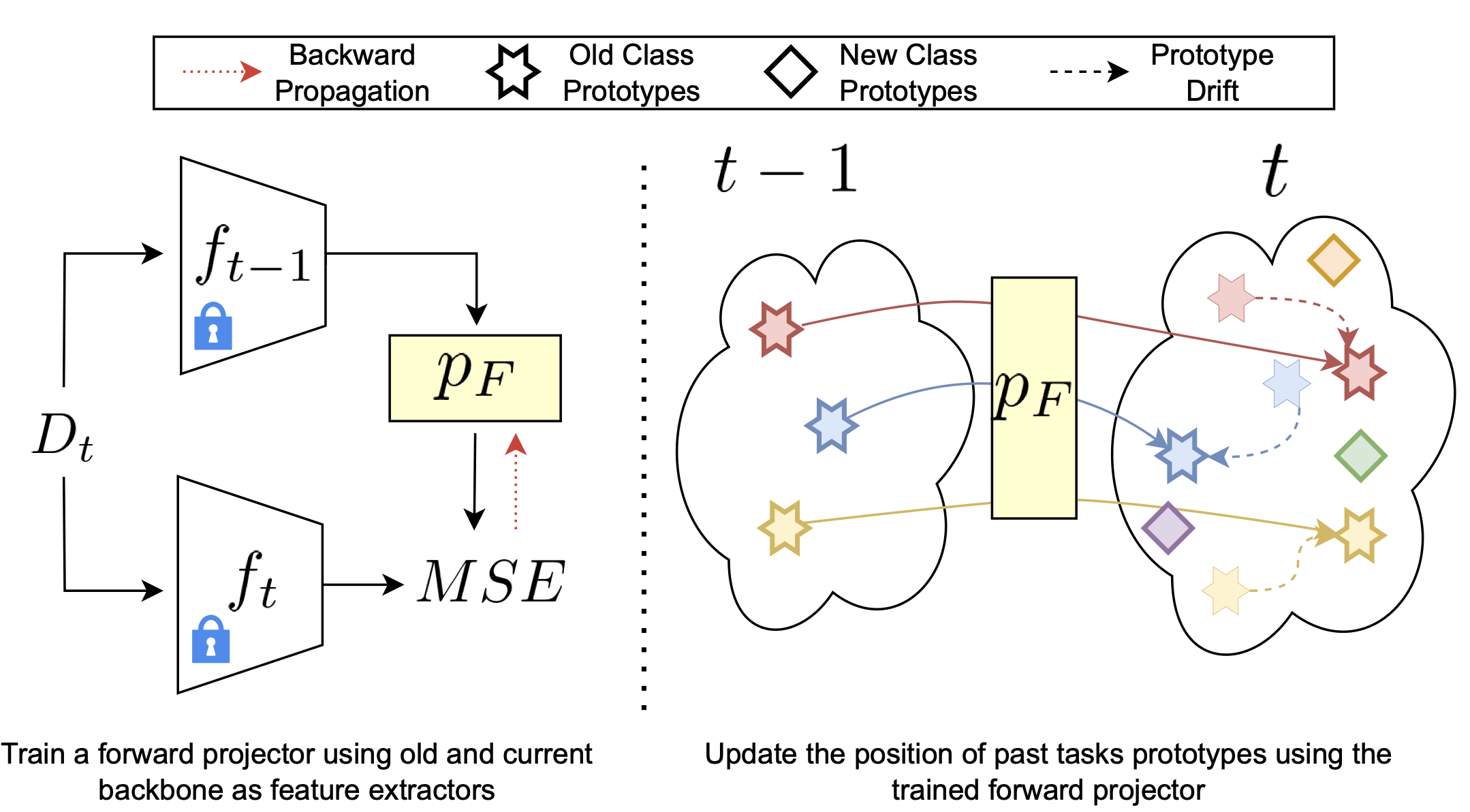 Exemplar-free Continual Representation Learning via Learnable Drift CompensationAlex Gomez-Villa, Dipam Goswami, Kai Wang, Andrew D Bagdanov, Bartlomiej Twardowski, and Joost Van De WeijerIn European Conference on Computer Vision (ECCV), 2024
Exemplar-free Continual Representation Learning via Learnable Drift CompensationAlex Gomez-Villa, Dipam Goswami, Kai Wang, Andrew D Bagdanov, Bartlomiej Twardowski, and Joost Van De WeijerIn European Conference on Computer Vision (ECCV), 2024Exemplar-free class-incremental learning using a backbone trained from scratch and starting from a small first task presents a significant challenge for continual representation learning. Prototype-based approaches, when continually updated, face the critical issue of semantic drift due to which the old class prototypes drift to different positions in the new feature space. Through an analysis of prototype-based continual learning, we show that forgetting is not due to diminished discriminative power of the feature extractor, and can potentially be corrected by drift compensation. To address this, we propose Learnable Drift Compensation (LDC), which can effectively mitigate drift in any moving backbone, whether supervised or unsupervised. LDC is fast and straightforward to integrate on top of existing continual learning approaches. Furthermore, we showcase how LDC can be applied in combination with self-supervised CL methods, resulting in the first exemplar-free semi-supervised continual learning approach. We achieve state-of-the-art performance in both supervised and semi-supervised settings across multiple datasets.
- Continual Learning
 Calibrating Higher-Order Statistics for Few-Shot Class-Incremental Learning with Pre-trained Vision TransformersDipam Goswami, Bartłomiej Twardowski, and Joost Van De WeijerIn CVPR Workshops - CLVISION, 2024
Calibrating Higher-Order Statistics for Few-Shot Class-Incremental Learning with Pre-trained Vision TransformersDipam Goswami, Bartłomiej Twardowski, and Joost Van De WeijerIn CVPR Workshops - CLVISION, 2024Few-shot class-incremental learning (FSCIL) aims to adapt the model to new classes from very few data (5 samples) without forgetting the previously learned classes. Recent works in many-shot CIL (MSCIL) (using all available training data) exploited pre-trained models to reduce forgetting and achieve better plasticity. In a similar fashion, we use ViT models pre-trained on large-scale datasets for few-shot settings, which face the critical issue of low plasticity. FSCIL methods start with a many-shot first task to learn a very good feature extractor and then move to the few-shot setting from the second task onwards. While the focus of most recent studies is on how to learn the many-shot first task so that the model generalizes to all future few-shot tasks, we explore in this work how to better model the few-shot data using pre-trained models, irrespective of how the first task is trained. Inspired by recent works in MSCIL, we explore how using higher-order feature statistics can influence the classification of few-shot classes. We identify the main challenge of obtaining a good covariance matrix from few-shot data and propose to calibrate the covariance matrix for new classes based on semantic similarity to the many-shot base classes. Using the calibrated feature statistics in combination with existing methods significantly improves few-shot continual classification on several FSCIL benchmarks.
- Continual Learning
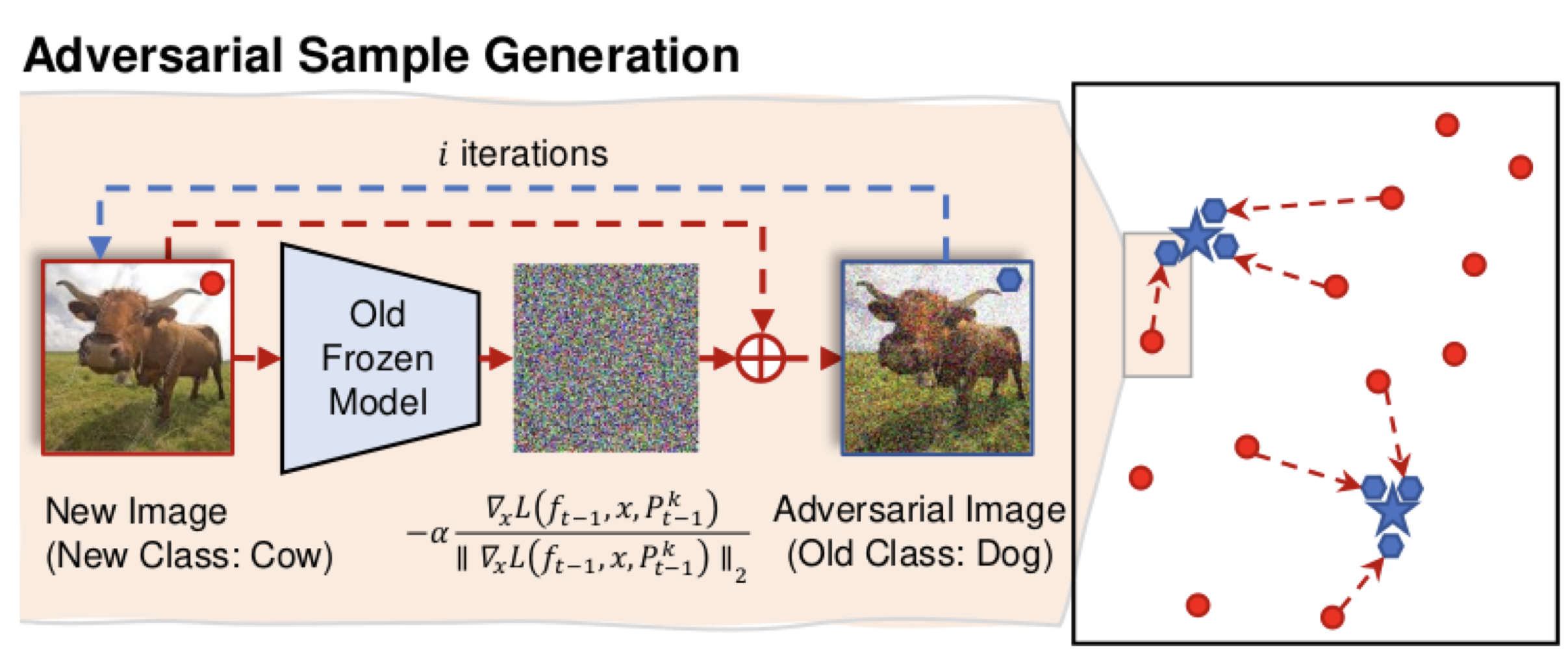 Resurrecting Old Classes with New Data for Exemplar-Free Continual LearningDipam Goswami, Albin Soutif-Cormerais, Yuyang Liu, Sandesh Kamath, Bartłomiej Twardowski, and Joost Van De WeijerIn Conference on Computer Vision and Pattern Recognition (CVPR), 2024
Resurrecting Old Classes with New Data for Exemplar-Free Continual LearningDipam Goswami, Albin Soutif-Cormerais, Yuyang Liu, Sandesh Kamath, Bartłomiej Twardowski, and Joost Van De WeijerIn Conference on Computer Vision and Pattern Recognition (CVPR), 2024Continual learning methods are known to suffer from catastrophic forgetting, a phenomenon that is particularly hard to counter for methods that do not store exemplars of previous tasks. Therefore, to reduce potential drift in the feature extractor, existing exemplar-free methods are typically evaluated in settings where the first task is significantly larger than subsequent tasks. Their performance drops drastically in more challenging settings starting with a smaller first task. To address this problem of feature drift estimation for exemplar-free methods, we propose to adversarially perturb the current samples such that their embeddings are close to the old class prototypes in the old model embedding space. We then estimate the drift in the embedding space from the old to the new model using the perturbed images and compensate the prototypes accordingly. We exploit the fact that adversarial samples are transferable from the old to the new feature space in a continual learning setting. The generation of these images is simple and computationally cheap. We demonstrate in our experiments that the proposed approach better tracks the movement of prototypes in embedding space and outperforms existing methods on several standard continual learning benchmarks as well as on fine-grained datasets.
2023
- Continual Learning
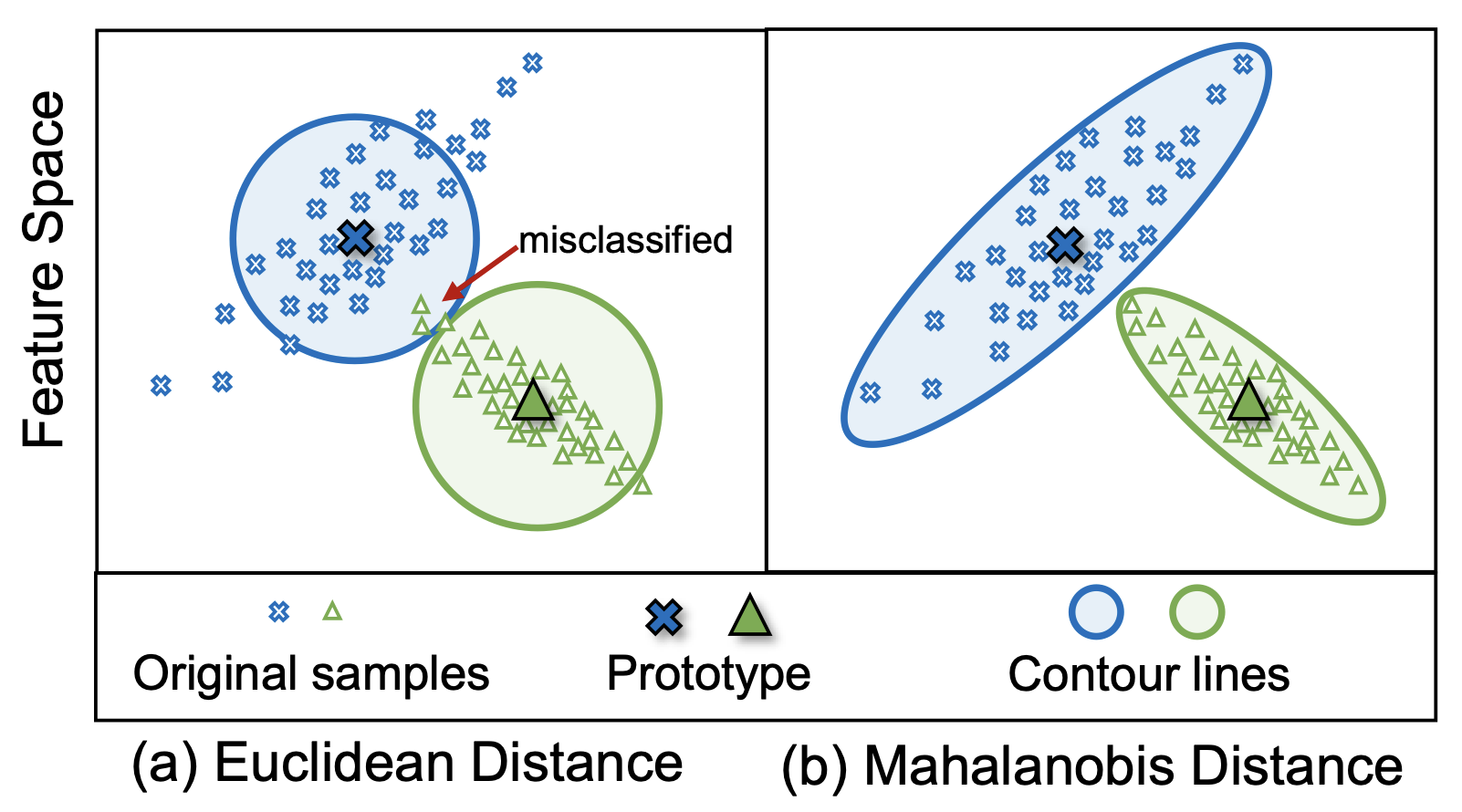 FeCAM: Exploiting the Heterogeneity of Class Distributions in Exemplar-Free Continual LearningDipam Goswami, Yuyang Liu, Bartłomiej Twardowski, and Joost Van De WeijerIn Advances in Neural Information Processing Systems (NeurIPS), 2023
FeCAM: Exploiting the Heterogeneity of Class Distributions in Exemplar-Free Continual LearningDipam Goswami, Yuyang Liu, Bartłomiej Twardowski, and Joost Van De WeijerIn Advances in Neural Information Processing Systems (NeurIPS), 2023Exemplar-free class-incremental learning (CIL) poses several challenges since it prohibits the rehearsal of data from previous tasks and thus suffers from catastrophic forgetting. Recent approaches to incrementally learning the classifier by freezing the feature extractor after the first task have gained much attention. In this paper, we explore prototypical networks for CIL, which generate new class prototypes using the frozen feature extractor and classify the features based on the Euclidean distance to the prototypes. In an analysis of the feature distributions of classes, we show that classification based on Euclidean metrics is successful for jointly trained features. However, when learning from non-stationary data, we observe that the Euclidean metric is suboptimal and that feature distributions are heterogeneous. To address this challenge, we revisit the anisotropic Mahalanobis distance for CIL. In addition, we empirically show that modeling the feature covariance relations is better than previous attempts at sampling features from normal distributions and training a linear classifier. Unlike existing methods, our approach generalizes to both many- and few-shot CIL settings, as well as to domain-incremental settings. Interestingly, without updating the backbone network, our method obtains state-of-the-art results on several standard continual learning benchmarks.
- Continual Learning
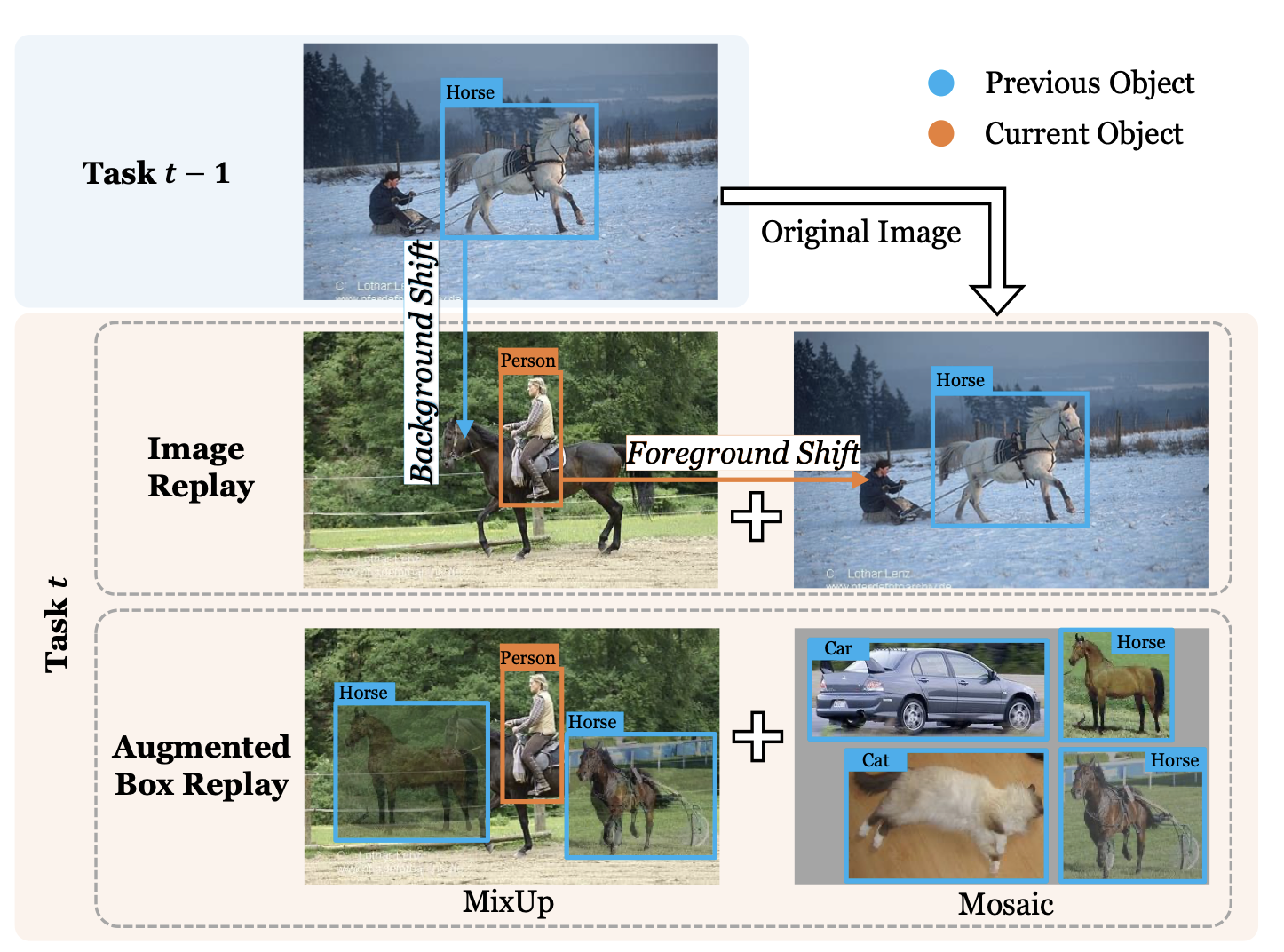 Augmented Box Replay: Overcoming Foreground Shift for Incremental Object DetectionYuyang Liu, Yang Cong, Dipam Goswami, Xialei Liu, and Joost Van De WeijerIn International Conference on Computer Vision (ICCV), 2023
Augmented Box Replay: Overcoming Foreground Shift for Incremental Object DetectionYuyang Liu, Yang Cong, Dipam Goswami, Xialei Liu, and Joost Van De WeijerIn International Conference on Computer Vision (ICCV), 2023In incremental learning, replaying stored samples from previous tasks together with current task samples is one of the most efficient approaches to address catastrophic forgetting. However, unlike incremental classification, image replay has not been successfully applied to incremental object detection (IOD). In this paper, we identify the overlooked problem of foreground shift as the main reason for this. Foreground shift only occurs when replaying images of previous tasks and refers to the fact that their background might contain foreground objects of the current task. To overcome this problem, a novel and efficient Augmented Box Replay (ABR) method is developed that only stores and replays foreground objects and thereby circumvents the foreground shift problem. In addition, we propose an innovative Attentive RoI Distillation loss that uses spatial attention from region-of-interest (RoI) features to constrain current model to focus on the most important information from old model. ABR significantly reduces forgetting of previous classes while maintaining high plasticity in current classes. Moreover, it considerably reduces the storage requirements when compared to standard image replay. Comprehensive experiments on Pascal-VOC and COCO datasets support the state-of-the-art performance of our model.
- Continual Learning
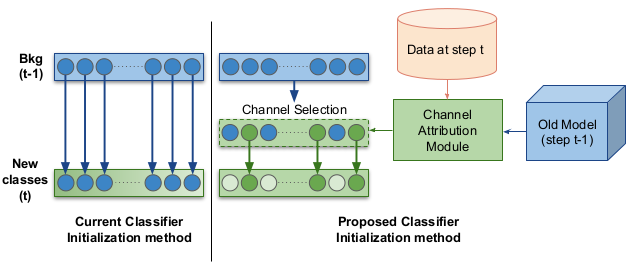 Attribution-aware weight transfer: A warm-start initialization for class-incremental semantic segmentationDipam Goswami, René Schuster, Joost Van De Weijer, and Didier StrickerIn Winter Conference on Applications of Computer Vision (WACV), 2023
Attribution-aware weight transfer: A warm-start initialization for class-incremental semantic segmentationDipam Goswami, René Schuster, Joost Van De Weijer, and Didier StrickerIn Winter Conference on Applications of Computer Vision (WACV), 2023In class-incremental semantic segmentation (CISS), deep learning architectures suffer from the critical problems of catastrophic forgetting and semantic background shift. Although recent works focused on these issues, existing classifier initialization methods do not address the background shift problem and assign the same initialization weights to both background and new foreground class classifiers. We propose to address the background shift with a novel classifier initialization method which employs gradient-based attribution to identify the most relevant weights for new classes from the classifier’s weights for the previous background and transfers these weights to the new classifier. This warm-start weight initialization provides a general solution applicable to several CISS methods. Furthermore, it accelerates learning of new classes while mitigating forgetting. Our experiments demonstrate significant improvement in mIoU compared to the state-of-the-art CISS methods on the Pascal-VOC 2012, ADE20K and Cityscapes datasets.
- Object Detection
 Bounding Box Priors for Cell Detection with Point AnnotationsHari Om Aggrawal, Dipam Goswami, and Vinti AgarwalIn IEEE 20th International Symposium on Biomedical Imaging (ISBI), 2023
Bounding Box Priors for Cell Detection with Point AnnotationsHari Om Aggrawal, Dipam Goswami, and Vinti AgarwalIn IEEE 20th International Symposium on Biomedical Imaging (ISBI), 2023The size of an individual cell type, such as a red blood cell, does not vary much among humans. We use this knowledge as a prior for classifying and detecting cells in images with only a few ground truth bounding box annotations, while most of the cells are annotated with points. This setting leads to weakly semi-supervised learning. We propose replacing points with either stochastic (ST) boxes or bounding box predictions during the training process. The proposed “mean-IOU” ST box maximizes the overlap with all the boxes belonging to the sample space with a class-specific approximated prior probability distribution of bounding boxes. Our method trains with both box- and point-labelled images in conjunction, unlike the existing methods, which train first with box- and then point-labelled images. In the most challenging setting, when only 5% images are box-labelled, quantitative experiments on a urine dataset show that our one-stage method outperforms two-stage methods by 5.56 mAP. Furthermore, we suggest an approach that partially answers “how many box-labelled annotations are necessary?” before training a machine learning model.
2021
- Floor Plans
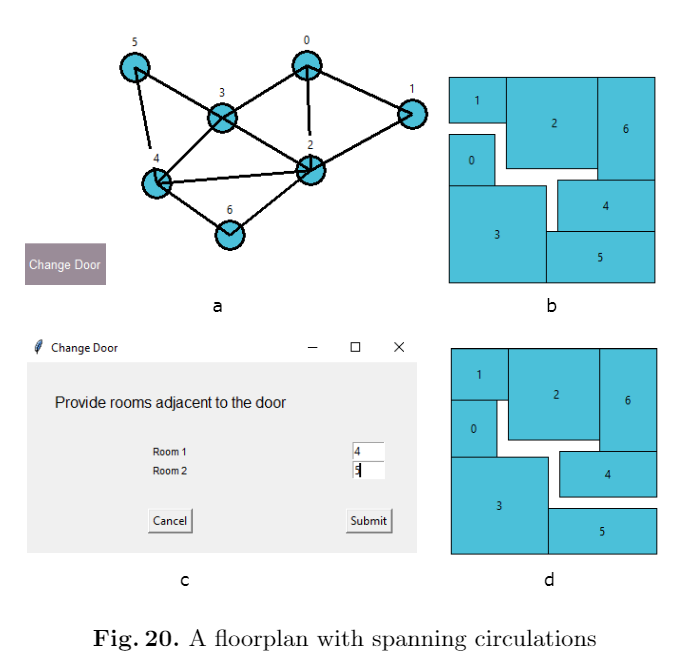 Graph-based approach for enumerating floorplans based on users specificationsKrishnendra Shekhawat, Rahil N Jain, Sumit Bisht, Aishwarya Kondaveeti, and Dipam GoswamiAI EDAM, Cambridge University Press, 2021
Graph-based approach for enumerating floorplans based on users specificationsKrishnendra Shekhawat, Rahil N Jain, Sumit Bisht, Aishwarya Kondaveeti, and Dipam GoswamiAI EDAM, Cambridge University Press, 2021
